
Artificial Intelligence Primer
Introducing the tech, critical language, and risks.


Artificial intelligence (AI) is creeping into our daily lives now, especially the lives of those who spend significant time online. But what is it? Every new technology carries advantages, disadvantages, and risks. What makes AI any different?
We hear dark mutterings about a future cohabiting the globe with AI and AI-powered robots, watch various portrayals in video media (“Matrix,” the visionary Spike Jonze film “Her,” the “Terminator” series, and so many others), and read about Neuralink, World Economic Forum admiration of a dark transhuman future -the Fourth Industrial Revolution, and hear echos of the “Silicon Valley” technocrats and thought leaders that have convinced themselves that the humans are obsolete and must be replaced by machines that will be more responsible stewards of both earth and the future.
Those who follow this substack and my various lectures and podcasts may have noticed that I am starting to explore the many ethical issues associated with Artificial Intelligence (AI) and the interfaces between humanity and AI. I am particularly interested in the interfaces of PsyWar and AI, human/transhumanism and AI, Austrian school economic theory and AI, and corporatism/globalism/global government and AI. Like many, I have a vague understanding of what is commonly referred to as AI, but I need more depth and expertise to understand the implications and ethics associated with this tech.
Are these topics too far “outside of my lane”? What is my relevant background and experience? Why should you, the reader, want to follow along on this exploratory journey?
From 1980 to 1982, I was a computer science student trained in computer architecture and programming (coding) fundamentals, including a handful of programming languages - some still used. During the early years of the COVIDcrisis, I collaborated closely with a highly skilled and experienced computer scientist employed at MIT Lincoln Laboratories (focusing on repurposing drugs for COVID treatment), and he coached me on the basics of Artificial Intelligence. More recently, I have invested a few years in developing an advanced understanding of PsyWar, transhumanism, and globalism. I have a solid background in bioethics and first-hand experience with the cultures and ethical issues arising during cutting-edge, innovative technical research and application development. I am skilled at reviewing, synthesizing, and summarizing technical information. I want to understand how AI will impact my life and those around me so that I can be more prepared for the future and mitigate some risks.
That is the toolkit I bring to address these issues. If you'd like to follow along with the resulting essays, we can then decide whether that is enough.
Let’s start by defining some key terms and concepts.
What is “Artificial Intelligence”
Artificial Intelligence (AI) refers to computer systems or algorithms that mimic intelligent human behavior. It enables machines to:
Reason and make decisions
Discover patterns and relationships in data
Generalize and apply knowledge to new situations
Learn from past experiences and adapt to new information
AI systems are developed by processing vast amounts of data to identify patterns, model decision-making, and generate outputs such as predictions, recommendations, or decisions. This capability has been achieved, in part, by studying the patterns of the human brain and analyzing cognitive processes. However, the current generation of “narrow” AI has more to do with comparative data-set analysis (“machine learning” or “deep learning”) than advanced concepts involving neural network modeling of the human brain and cognition, although current concepts in human neurobiology are being applied to inform the development of advanced artificial intelligence capabilities.
You may be wondering whether computer-based AI can achieve consciousness or sentience. If so, you will enjoy reading this essay published in Psychology Today by physician Robert Lanza, one of the leading proponents of the emerging thought space known as “Biocentrism.”
Key aspects of AI:
Imitation of human intelligence: AI systems simulate human-like thinking and behavior.
Computer-controlled: AI is executed by software or algorithms running on computers or robots.
Autonomous decision-making: AI systems make decisions based on their programming and data analysis.
Is AI the same as machine learning?
Machine learning (and deep learning) are methods developed to train a computer to learn from its inputs without explicit programming for every circumstance. Machine and deep learning can also be used to train a digital computation system to achieve narrow artificial intelligence.
What is machine learning?
Machine learning involves the comparative processing of large data sets to detect patterns, associations, and relationships. The resulting information is used to generate various summaries, recommendations, or predictions concerning general phenomena.

Sara Brown, writing for the MIT Sloan school of Management, explains;
Machine learning starts with data — numbers, photos, or text, like bank transactions, pictures of people or even bakery items, repair records, time series data from sensors, or sales reports. The data is gathered and prepared to be used as training data, or the information the machine learning model will be trained on. The more data, the better the program.
From there, programmers choose a machine learning model to use, supply the data, and let the computer model train itself to find patterns or make predictions. Over time the human programmer can also tweak the model, including changing its parameters, to help push it toward more accurate results. (Research scientist Janelle Shane’s website AI Weirdness is an entertaining look at how machine learning algorithms learn and how they can get things wrong — as happened when an algorithm tried to generate recipes and created Chocolate Chicken Chicken Cake.)
The process involves developing a large data set, splitting those data into two or more groups (training and validation sets), analyzing one data set for patterns and predictions to create a model of the underlying reality sampled by the training set, testing whether those patterns and predictions derived from the training set hold when applied to the validation set(s) and then repeating the process when necessary to refine the model of “reality” as represented by the data.
Returning back to Sarah Brown;
There are three subcategories of machine learning:
Supervised machine learning models are trained with labeled data sets, which allow the models to learn and grow more accurate over time. For example, an algorithm would be trained with pictures of dogs and other things, all labeled by humans, and the machine would learn ways to identify pictures of dogs on its own. Supervised machine learning is the most common type used today.
In unsupervised machine learning, a program looks for patterns in unlabeled data. Unsupervised machine learning can find patterns or trends that people aren’t explicitly looking for. For example, an unsupervised machine learning program could look through online sales data and identify different types of clients making purchases.
Reinforcement machine learning trains machines through trial and error to take the best action by establishing a reward system. Reinforcement learning can train models to play games or train autonomous vehicles to drive by telling the machine when it made the right decisions, which helps it learn over time what actions it should take.
Brown explains that Machine learning is also associated with several other artificial intelligence subfields:
Natural language processing
Natural language processing is a field of machine learning in which machines learn to understand natural language as spoken and written by humans, instead of the data and numbers normally used to program computers. This allows machines to recognize language, understand it, and respond to it, as well as create new text and translate between languages. Natural language processing enables familiar technology like chatbots and digital assistants like Siri or Alexa.
Neural networks
Neural networks are a commonly used, specific class of machine learning algorithms. Artificial neural networks are modeled on the human brain, in which thousands or millions of processing nodes are interconnected and organized into layers.
In an artificial neural network, cells, or nodes, are connected, with each cell processing inputs and producing an output that is sent to other neurons. Labeled data moves through the nodes, or cells, with each cell performing a different function. In a neural network trained to identify whether a picture contains a cat or not, the different nodes would assess the information and arrive at an output that indicates whether a picture features a cat.
Deep learning
Deep learning networks are neural networks with many layers. The layered network can process extensive amounts of data and determine the “weight” of each link in the network — for example, in an image recognition system, some layers of the neural network might detect individual features of a face, like eyes, nose, or mouth, while another layer would be able to tell whether those features appear in a way that indicates a face.
Like neural networks, deep learning is modeled on the way the human brain works and powers many machine learning uses, like autonomous vehicles, chatbots, and medical diagnostics.
What are the different categories of Artificial Intelligence: Narrow, General, and Super AI
To answer this question, I have selected content (edited for clarity) from an article by V.K. Anirudh for the website Spiceworks.com.
Narrow Artificial Intelligence
Narrow AI is the most prevalent kind of AI today, and is found in a wide variety of mobile phone applications, Internet search engines, and big data analytics. Most of the AI that you currently encounter or use involves narrow AI.
The name stems from the fact that these artificial intelligence systems are explicitly created for a single task. Owing to this narrow approach and inability to perform tasks other than those that are specified to them, they are also called ‘weak’ AI. This makes their “intelligence” highly focused on one task or set of tasks, allowing for further optimization and tweaking. Because these systems are limited to the tasks assigned to them, they are also known as "weak" AI.
Narrow AI is created using current standards and tools
With the increase in the adoption of AI by enterprises, the technology is expected to do one thing well. Narrow AI is developed in an environment where the problem is front-and-center, using the latest technology.
Owing to its high efficiency, speed, and human consumption rate, narrow artificial intelligence has become one of many corporations' go-to solutions. For various low-level tasks, narrow AI can employ intelligent automation and integration to provide efficiency while maintaining accuracy.
This makes it a favored choice for tasks that involve million-scale datasets, known as big data. With personal data collection prevalent (see Surveillance Capitalism and PsyWar), companies have a large amount of big data at their disposal that can be used to train AI and derive insights.
Types of Artificial Intelligence

In order to differentiate between the degree to which AI applications can conduct tasks, they are generally split into three types. These types are distinct from each other and show the natural progression to AI systems today.
Narrow Artificial Intelligence
Narrow AI is the most prevalent kind of AI today. From applications in mobile phones to the Internet to big data analytics, narrow AI is taking the world by storm.
The name stems from the fact that this kind of artificial intelligence systems are explicitly created for a single task. Owing to this narrow approach and inability to perform tasks other than the ones that are specified to them, they are also called as ‘weak’ AI. This makes their intelligence highly-focused on one task or set of tasks, allowing for further optimization and tweaking.
Why Is It Called Narrow Intelligence?
Narrow AI is designed for specific tasks and cannot perform tasks other than the ones specified to it. This narrow focus is mainly due to the following factors:
Narrow AI is a Complex Computer Program
Narrow AI is usually restricted in its scope because it is created to solve a problem. It is built with the explicit focus of ensuring that a task is completed, with its architecture and functioning representing this.
Today’s narrow AI is not made up of non-quantifiable parts; it is just a computer program running as per the instructions given to it. Due to these constraints and specified use-case, narrow AI has a laser focus on the tasks it was created for.
Narrow AI is Created as per Today’s Standards and Tools
With the increase in adoption of AI by enterprises, the technology is expected to do one thing and do it well. While the use-case might differ from company to company, the expectations are the same – an exponential increase to the bottom line. Today, this can be done only with narrow AI.Narrow AI is developed in an environment where the problem is front-and-center, using the latest technology. Artificial intelligence, in general, is a highly research-oriented field, and the research groundwork to create something more than a single use-case system has not been laid out yet. This creates AI with a narrow focus.
Owing to its high efficiency, speed, and consumption rate over humans, narrow artificial intelligence is one of the go-to solutions for corporates. For a wide variety of low-level tasks, narrow AI can employ smart automation and integration to provide efficiency while maintaining accuracy.
This makes it a favored choice for tasks that involve million-scale datasets, known as big data. With personal data collection being prevalent, companies have a large amount of big data at their disposal that can be used for training AI and deriving insights from it.
Examples of Narrow AI include:
Recommendation Systems
Whenever you see a ‘recommended’ tag on a website, it is usually put there by a narrow AI. By looking at a user’s preferences with respect to the database of content or information, an AI is able to determine their likes and dislikes.
This is then used to offer recommendations, thus providing a more personalized experience to the user. This is commonly seen on sites, such as Netflix (“Because you watched…”), YouTube (“Recommended”), Twitter (“Top Tweets first”), and many more services.Spam Filtering
Narrow AI with natural language processing capabilities is employed to keep our inboxes clean. Employees cannot check every spam email they receive, but it’s a perfect task for narrow AI.
Google is the leader in providing email services and has evolved its narrow AI to a point where it conducts various email-related tasks. Along with AI-powered spam filters, they can also assign a category to a particular type of email (promotions, reminders, important, and so on).Expert Systems
Narrow AI has the capability to create expert systems, which could pave the way for the future of AI. Just as human intelligence is comprised of various senses and logical, creative, and cognitive tasks; expert systems also consist of many parts.
Expert systems may represent the future of artificial intelligence. This term is used to denote an AI system made up of many smaller narrow AI algorithms. For example, IBM Watson is made of a natural language processing component along with a cognitive aspect.Battle Drones
Narrow AI-enabled autonomous battle drones are currently being developed, tested, and deployed in Ukraine.
Artificial General Intelligence (AGI)
While narrow AI refers to where artificial intelligence has reached today, general AI refers to where it will be in the future. Also known as artificial general intelligence (AGI) and strong AI, general artificial intelligence is a type of AI that can think and function more like humans do. This includes perceptual tasks, such as vision and language processing, along with cognitive tasks, such as processing, contextual understanding, thinking, and a more generalized approach to thinking as a whole.
While narrow AI is created as a means to execute a specific task, AGI can be broad and adaptable. The learning part of adaptive general intelligence also has to be unsupervised, as opposed to the supervised and labeled learning that narrow AI is put through today.
Tools required to build AGI are not available today. Many argue that neural networks are a dependable way to create the forerunners of what can be called artificial general intelligence, but human intelligence is still a black box. There is a school of thought that AGI will be achieved within the next three years, and some believe that a partial AGI may already exist within some corporations that seek to develop AGI for commercial purposes.
While humans are beginning to decode the inner workings of our minds and brains, we are still a long way from figuring out what ‘intelligence’ means. In addition to this obstacle, the need to define ‘consciousness’ is integral to creating a general AI. This is because an AGI needs to be ‘conscious’ and not just an algorithm or machine.
The Elon Musk company, Tesla, is currently developing a multi-purpose robot (Tesla Optimus) intended for general consumers that may eventually incorporate onboard AGI capabilities. Imagine a home robot with the equivalent of one hundred PhD degrees. The anticipated retail price point is approximately $20,000 US.
Artificial Super Intelligence
Artificial superintelligence (ASI) is a term used to denote an AI that exceeds human cognition in every possible way. This is one of the most far-off theories of artificial intelligence, but it is generally considered to be the eventual endgame of creating an AI.
While artificial superintelligence is still a theory at this point in time, a lot of scenarios involving it have already been envisioned. A common consensus among those in the field is that ASI will come from the exponential growth of AI algorithms, also known as the ‘Intelligence Explosion.’
Intelligence explosion is a concept required for the creation of artificial superintelligence. As the name suggests, it is an explosion of intelligence from human-level, general artificial intelligence to an unthinkable level. This is anticipated to occur through recursive self-improvement (self-learning).
Self-improvement in AI comes in the form of learning from user input in neural networks. Recursive self-improvement, on the other hand, is the capacity of an AI system to learn from itself, at rapidly increasing levels of increasing intelligence.
To illustrate this, consider an AGI functioning at the level of average human intelligence. It will learn from itself, using the cognitive capabilities of an average human, to reach genius-level intelligence. However, this begins compounding, and any future learning made by the AI will be conducted at a genius-level cognitive functioning.
This accelerates at a fast pace, creating an intelligence that is smarter than itself at every step. This continues to build up quickly until the point where intelligence explodes, and a superintelligence is born.
Many leaders in this area anticipate that once a self-learning enabled AGI is created, then it will evolve into an ASI within months.
What are the risks of Artificial Intelligence?
The Massachusetts Institute of Technology (MIT) Computer Science & Artificial Intelligence Laboratory (CSAIL) has recently developed the world’s first comprehensive database dedicated to cataloging the various risks associated with artificial intelligence and has made this resource available to the public. This new resource, known as the AI Risk Repository, is the result of a collaborative international effort to catalog the various ways AI technologies can create problems, making it an important project for policymakers, researchers, ethicists, developers, IT professionals, and the general public.
The new database categorizes 700 different risks, ranging from technical failures to cybersecurity vulnerabilities to ethical concerns and other impacts on society. Until now, no centralized resource has been available to list and categorize the risks associated with these technologies. Currently, there is no recognized authority, think tank, or governance structure dedicated to assessing these risks and providing rules or guidance concerning how corporations or other interested parties should manage these risks. This situation is very similar to the early days of atomic energy, recombinant DNA, or infectious pathogen gain-of-function research.
The AI Risk Repository has three parts:
The AI Risk Database captures 700+ risks extracted from 43 existing frameworks, with quotes and page numbers.
The Causal Taxonomy of AI Risks classifies how, when, and why these risks occur.
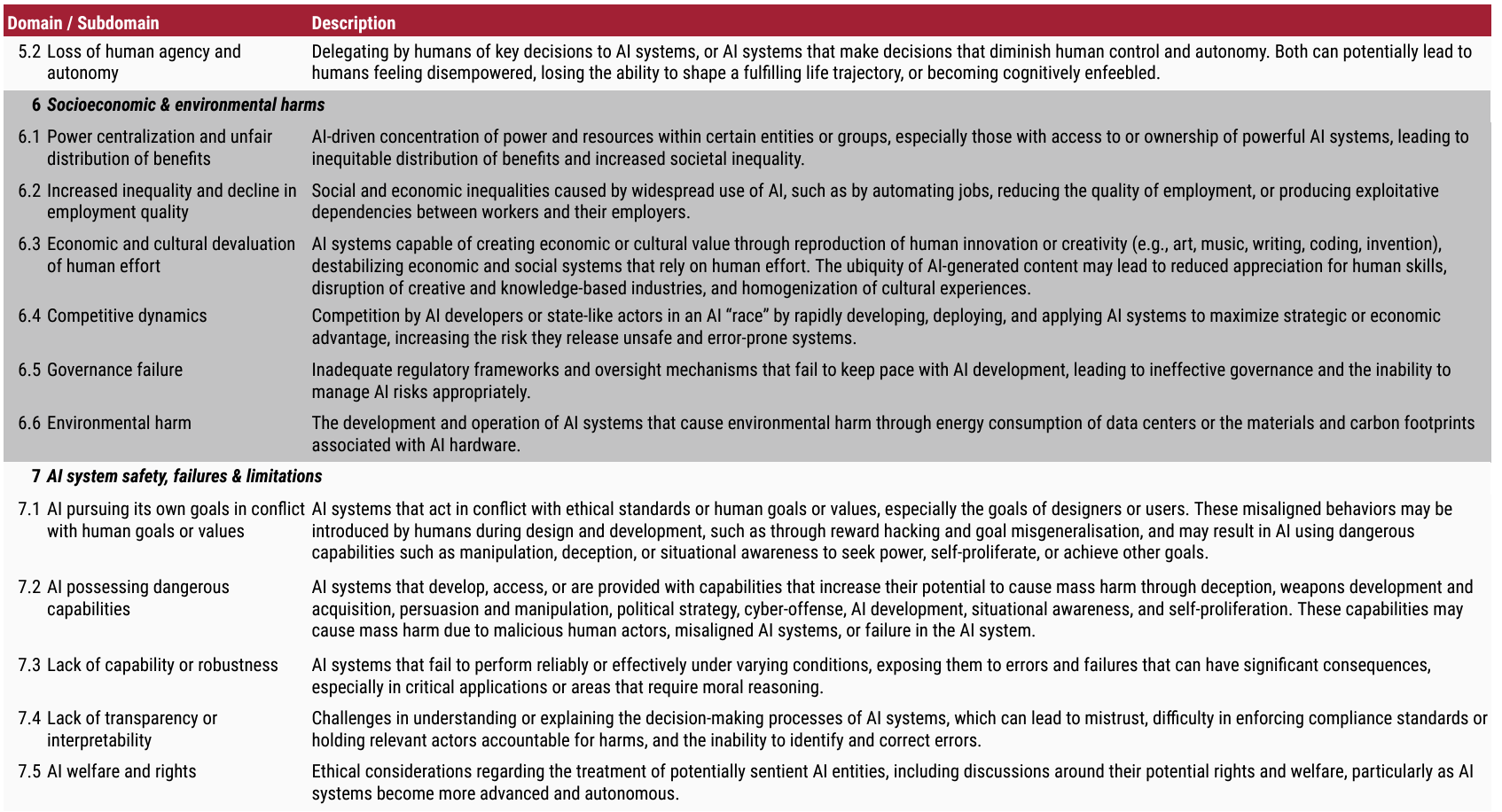
The Domain Taxonomy of AI Risks classifies these risks into seven domains (e.g., “Misinformation”) and 23 subdomains (e.g., “False or misleading information”).
The Domain Taxonomy of AI Risks classifies risks from AI into seven domains and 23 subdomains.

The team that developed this new resource has summarized their work in a brief abstract written in plain language for a general audience.
The risks posed by Artificial Intelligence (AI) concern many stakeholders
Many researchers have attempted to classify these risks
Existing classifications are uncoordinated and inconsistent
We review and synthesize prior classifications to produce an AI Risk Repository, including a paper, causal taxonomy, domain taxonomy, database, and website
To our knowledge, this is the first attempt to rigorously curate, analyze, and extract AI risk frameworks into a publicly accessible, comprehensive, extensible, and categorized risk database
The risks posed by Artificial Intelligence (AI) are of considerable concern to a wide range of stakeholders including policymakers, experts, AI companies, and the public. These risks span various domains and can manifest in different ways: The AI Incident Database now includes over 3,000 real-world instances where AI systems have caused or nearly caused harm.
To create a clearer overview of this complex set of risks, many researchers have tried to identify and group them. In theory, these efforts should help to simplify complexity, identify patterns, highlight gaps, and facilitate effective communication and risk prevention. In practice, these efforts have often been uncoordinated and varied in their scope and focus, leading to numerous conflicting classification systems. Even when different classification systems use similar terms for risks (e.g., “privacy”) or focus on similar domains (e.g., “existential risks”), they can refer to concepts inconsistently. As a result, it is still hard to understand the full scope of AI risk. In this work, we build on previous efforts to classify AI risks by combining their diverse perspectives into a comprehensive, unified classification system.
During this synthesis process, we realized that our results contained two types of classification systems:
High-level categorizations of causes of AI risks (e.g., when or why risks from AI occur)
Mid-level hazards or harms from AI (e.g, AI is trained on limited data or used to make weapons)
Because these classification systems were so different, it was hard to unify them; high-level risk categories such as “Diffusion of responsibility” or “Humans create dangerous AI by mistake” do not map to narrower categories like “Misuse” or “Noisy Training Data,” or vice versa. We, therefore, decided to create two different classification systems that together would form our unified classification system. The paper we produced and its associated products (i.e., causal taxonomy, domain taxonomy, living database, and website) provides a clear, accessible resource for understanding and addressing a comprehensive range of risks associated with AI. We refer to these products as the AI Risk Repository.
The brief table (below) that summarizes the team’s findings by Domain Taxonomy provides a convenient overview of current thinking concerning the risks associated with Artificial Intelligence.

As mentioned above, there is currently no national or international body or structure akin to the International Atomic Energy Agency established to assess or provide guidance concerning these risks and how they should be managed and mitigated. The US-based Union of Concerned Scientists (UCS) is beginning to highlight issues involving AI development and safety risks a priority.
On October 30, 2023 the White House issued a new executive order on the use of artificial intelligence (AI) technology, laying out guidelines to protect safety, privacy, equity, and the rights of consumers, patients and workers.
In response, Dr. Jennifer Jones, director of the Center for Science and Democracy at the UCS issued the following statement:
“Artificial intelligence technologies have real potential to change the way we go about our lives—but we can’t just assume they’ll work for the public benefit. These technologies are consequential and come with real risks, and we need to use our own intelligence in making sure we manage the risks. This effort will require collaboration among governments, businesses, scientists, and community organizations.
“AI technology has grown rapidly, but raises important questions. How will we make sure people can get accurate and reliable information from the sea of AI-generated content? How do we make sure that AI systems aren’t built to replicate the racial, gender, and class biases that lead to discrimination and oppression? Can we make sure that AI tools don’t just become another source of disinformation and opportunity for exploitation by bad actors? How will AI-generated information be used in government decision-making?
“This executive order is a good first step that addresses some—but not all—of the vital questions about AI technology. It has solid language around protecting individual privacy and looks across multiple issues that intersect with AI. A broader set of AI guidance should include efforts to protect against disinformation, ensure equitable access to technology, defend free and fair elections, and coordinate with the communities and groups most likely to be impacted by AI. In addition, the White House Office of Science and Technology Policy should examine and issue a report on the relationship between AI technology and scientific integrity.
“We need to make thoughtful, intentional choices about how we deploy technologies—choices that are centered around people, not the technologies themselves. Today’s executive order is a step in the right direction, but more work on this issue will certainly be needed. We’ll be watching closely to ensure that the federal government provides effective and comprehensive guidance on the use of AI technologies.”
In Conclusion
Artificial Intelligence (AI) and the interfaces between AI, robotics technology, and technology that enable direct linkage between human brains and computational systems and networks will disrupt our world in a myriad of ways that we are only beginning to anticipate. This body of knowledge and capabilities is being and will continue to be exploited for a wide range of commercial and political interests and will challenge and transform the world we live in. It is hard to imagine if it will even be possible to regulate and mitigate the many associated risks, given the fragmented, multilateral nature of current global political structures. Yet the lessons of the recent past demonstrate that the imposition of global governance structures onto this technology will further advance global corporatism and totalitarianism.
The World Economic Forum (WEF) has been promoting a transhumanist agenda based in part on futuristic projections concerning robotics and artificial intelligence, particularly through its “Great Reset” initiative. This vision envisions a future where humanity is augmented and transformed through technology, leading to a new era of human evolution.
Key Points:
The Great Reset: The WEF’s plan for a post-coronavirus world, which includes harnessing the innovations of the Fourth Industrial Revolution to support the public good. This involves integrating technologies that will change what it means to be human, such as brain-computer interfaces, nanotechnology, and synthetic biology.
Transhumanist Goals: The WEF’s transhumanist vision aims to overcome human limitations, including aging, sickness, and death, through technological advancements. This includes:
Immortality through nanorobots, genetic engineering, and digital brain uploading.
Permanent happiness through “happiness drugs” and brain-chip interfaces.
Human beings becoming “god-like” creators, able to manipulate the material world and create new forms of life.
Dataism: Yuval Noah Harari, a key advisor to the WEF, proposes a “data religion” where data (information processing) replaces God or human nature as the ultimate source of meaning and authority. In this future, a self-improving superintelligent AI would know us better than we know ourselves and function as a kind of omniscient oracle or sovereign.
Ethical Concerns: The WEF’s transhumanist agenda raises ethical questions about the limits of human enhancement, the potential for authoritarianism, and the implications for democracy and individual freedom.
Notable Relevant WEF Quotes:
“This digital identity determines what products, services and information we can access – or, conversely, what is closed off to us.” – World Economic Forum, 2018
“Authoritarianism is easier in a world of total visibility and traceability, while democracy may turn out to be more difficult.” – World Economic Forum, 2019
Release and shipping is on track for early October 2024. Pre-purchase link here.
Glad that y’all are enjoying this one. It is technical and nerdy, and i thought it would not get much of a response. As i put it together i thought it a sort of necessary evil….
At a (Lead Paint Certification)class today. The biggest concern of mine is who controls what AI does? Consider an authoritarian government having control of what a population is taught, compared to a free society. Think freedom or tyranny. Think Trump or Harris. The saying elections have consequences never before seemed so consequential as it does today!